.png?width=888&height=337&ext=.png)
Demographic Horizons™
Dependants modelling
Dependant proportion and age difference assumptions are important for pricing longevity reinsurance, bulk annuities, and also in an ongoing pension scheme funding context. They can be as material as longevity assumptions, with differences in best estimate assumptions between schemes equivalent to 3% of liabilities, or more.
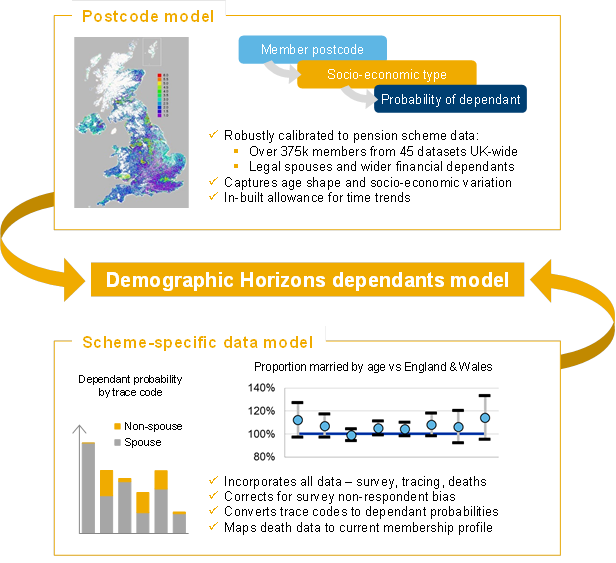
Recognising the significance of these assumptions, Aon has invested heavily in research in this area. Building on our position as leading risk adviser, we have unrivalled access to huge volumes of marital data, covering over 375,000 members and 45 datasets. Our data covers a wide range of different types of members, and both ‘legal spouse’ and ‘wider financial dependants’ eligibility criteria. It covers current and former pensioners, and includes multiple overlapping data sources, allowing us to robustly analyse the reliability of different types of data.
Our research covers each of the four key data sources pension schemes may have available:
- Survey data – Data from writing to members directly – the ‘gold standard’ when pricing dependants. However, survey wording can be unclear, so responses need to be interpreted carefully. Response rates can also vary significantly between surveys and can be heavily biased towards those who are married.
- Tracing data – Third-party tracing services can be used to estimate members’ statuses. These services are lower cost than surveys and don’t involve contacting members directly. However, taking the ‘trace codes’ at face value (for example, assuming an individual who is traced as ‘single’ has 0% possibility of having a dependant) can lead to biased conclusions. Instead, these trace codes need mapping to realistic probabilities of having a dependant.
- Past deaths data – Deceased and current members may differ in terms of age profile, socio- economic profile and effective date of information. And mortality rates are lower for married than unmarried individuals, even after controlling for these factors. So a simplistic analysis of deaths data would not be expected to accurately predict assumptions for current lives.
- Membership profile data – There is significant variation in marital data between groups, depending on factors such as age, gender and affluence.
Our research has allowed us to quantify biases within each of these data sources, and develop the Demographic Horizons dependants model. This model has been used extensively with pension schemes and (re)insurers since its introduction in 2019. The model uses a credibility-based framework to combine any available data sources, after correcting for any biases. Like our mortality model, we have tested our dependants model using a formal cross-validation approach, allowing us to quantify how predictive the model is and place confidence intervals around the assumptions produced.
For more information about the Demographic Horizons dependants model, please contact Richard Thornley or any of the Demographic Horizons team.